[Week 04] Lectures
# Useful functions
sample(X, #sample, replace = FALSE, ...)
[41 sample split]
sample
- random-sampling with and without (default) replacement
set.seed(2018)
x <- 1:20
sample(x, 10) # 20개 중에 10개 랜덤 추출
## [1] 7 9 2 4 8 5 19 18 12 20
sample(x, 10, replace = TRUE) # replace = TRUE; 중복허용
## [1] 8 14 20 14 17 13 6 12 15 17
sample(x, 10, replace = FALSE) # replace = FALSE; 중복불허
## [1] 6 11 3 2 13 9 5 16 8 1
# Random Shuffling
# 10개 중 10개를 랜덤하게 추출하면 랜덤 정렬이랑 같다.
x <- 1:10
sample(x, length(x))
Split
split(df, split_var, ...)
- split a data frame into a list of data frames with split variable
# mpg가 20을 초과하면 TRUE, 아니면 FALSE
split(mtcars, mtcars$mpg > 20)

Subset
- subset(df, condition, ...)
- Find a subset of dataframe with a criteria
subset(mtcars, mpg > 25)
mtcars[mtcars$mpg > 25, ]

[42 merge which]
Merge
Merge(df1, df2, ...)
- Join two data frames into one with common variables
x <- data.frame( name = c("John", "Bob", "Carol"), math = c(70, 80, 90))
y <- data.frame( name = c("John", "Bob", "Alice"), history = c(100, 55, 75))
x ## name math
## 1 John 70
## 2 Bob 80
## 3 Carol 90
y
## name history
## 1 John 100
## 2 Bob 55
## 3 Alice 75
merge(x, y)
## name math history
## 1 Bob 80 55
## 2 John 70 100
merge(x, y, all = T)
## name math history
## 1 Bob 80 55
## 2 Carol 90 NA
## 3 John 70 100
## 4 Alice NA 75
Which
- Find positions of elements that satisfy the condition
x <- c(5, 1, 2, 6, 3, 17, 8, 9, 12)
# 10을 초과하는 엘리먼트의 인덱스를 벡터로 반환
myindex <- which( x > 10)
# myindex 벡터변수는 x 벡터의 엘리먼트 중 10을 초과하는 엘리먼트의 인덱스를 벡터 형태로 가지고 있음.
myindex
## [1] 6 9
x[myindex]
## [1] 17 12
which.max which.min
- Find positions of maximum and minimum elements
x
## [1] 5 1 2 6 3 17 8 9 12
# x 벡터의 최대값 엘리먼트의 인덱스를 반환한다
which.max(x)
## [1] 6
# x 벡터의 최소값 엘리먼트의 인덱스를 반환한다
which.min(x)
## [1] 2
x[which.max(x)]
## [1] 17
x[which.min(x)]
## [1] 1
[43 cut]
- makes a range-group(factor) variable
mtcars$wt

# 데이터 프레임의 새로운 cut column 만들기
# wt에 해당하는 breaks가 새로운 칼럼이 된다.
mtcars$wt_grp <- cut(mtcar$wt, breaks = c(0, 2, 4, 6))
#
mtcars[, c('wt', 'wt_grp')]

# 숫자 범위가 아닌 레이블을 지정할 수도 있다
mtcars$wt_grp <- cut(mtcar$wt, breaks = c(0, 2, 4, 6), labels = c('light', 'normal', 'heavy'))
# ( ]. 오른쪽을 포함하고 싶으면 right = T
cut(mtcars$wt, breaks = c(0, 2, 4, 6), right = T)
# [ ). 왼쪽을 포함하고 싶으면 right = F
cut(mtcars$wt, breaks = c(0, 2, 4, 6), right = F)
[44 quantile and table]
quantile
- to find out percentiles
quantile(iris$Sepal.Length)

quantile(iris$Sepal.Length, probs = c(0.1, 0.5, 0.9))

hist(iris$Sepal.Length)

# quantile 함수로 0%, 25%, 75%, 100%의 구간에 위치한 엘리먼트를 cut_points 벡터에 저장한다.
cut_points <- quantile(mtcars$mpg, c(0, 0.25, 0.75, 1))
# cut_points는 0%, 25%, 75%, 100%에 위치한 mtcars$mpg의 엘리먼트를 가지고 있다.
# 그것을 cut - breaks에 넣어 새로운 column 'fuel_efficiency'를 만든다.
# include.lowest는 최소값도 포함할 것이냐는 것이다. 왜냐면 include.lowest가 F이면
mtcars$fuel_efficiency <- cut(mtcars$mpg, breaks = cut_points, include.lowest = T)
head(mtcars[, c('mpg', 'fuel_efficiency')], 10)

levels(mtcars$fuel_efficiency) <- c('low25perc', 'normal', 'high25perc')
head(mtcars[, c('mpg', 'fuel_efficiency')], 10)

frequency table
# 구간 별 몇개 씩 분포되어있는지 확인한다
table(mtcars$fuel_efficiency)
##
## low25perc normal high25perc
## 8 17 7
# 실린더 구간 별 몇 개 씩 분포되어 있는지 확인한다
table(mtcars$cyl)
##
## 4 6 8
## 11 7 14
#
table(mtcars$fuel_efficiency, mtcars$cyl)

[45 paste]
paste and paste0
- to concatenate several values into one string
- to concatenate element by element from 2 or more vectors
- to smash vector elements into one string
paste("one", 1, "test")
## [1] "one 1 test"
x <- seq(2, 20, 2)
y <- LETTERS[1:10]
paste(x, y)
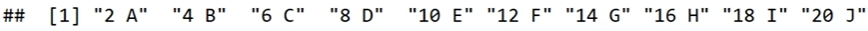
paste(x, y, sep = ":")

- need to use 'sep' and 'collapse' option properly
- useful to generate column names and row names
- paste0 equals to paste(..., sep = '')
- paste는 스페이스를 주고 합체
- paste0은 스페이스 없이 합체
paste('var', x)
paste0('var', x)
paste('var', x, y, sep = '-')
paste(x)
paste(x, collapse = ',')
paste(paste0(x, y), collapse = ',')

test.df <- data.frame(year = c(2019, 2020, 2016), month = c(4, 5, 7), day = c(10, 15, 20)
test.df

test.df$date <- paste(test.df$year, test.df$month, test.df$day)
test.df$date

test.df$date <- paste(test.df$year, test.df$month, test.df$day, sep = '-')
test.df$date
test.df$name <- c('John', 'Bob', 'Carol')
test.df$name
paste(test.df$name, collapse = ',')
[1] "John,Bob,Carol"
names(mtcars)
input_vars = names(mtcars)[2:6]
input_vars
[1] "cyl" "disp" "hp" "drat" "wt"
paste(input_vars, collapse = '+')
[1] "cyl+disp+hp+drat+wt"
paste(input_vars, collapse = ' + ')
[1] "cyl + disp + hp + drat + wt"
outcome = 'mpg'
paste(outcome, paste(input_vars, collapse = ' + '), sep = ' ~ ')
[1] "mpg ~ cyl + disp + hp + drat + wt"
'공부 > R Programming' 카테고리의 다른 글
| pums.sample R (0) | 2021.04.17 |
|---|---|
| [Week 06] Lectures (0) | 2021.04.09 |
| [Week 03] Lectures (0) | 2021.03.28 |
| Data Science Week 03 - 02 (0) | 2021.03.19 |
| Data Science Week 03 - 01 (0) | 2021.03.18 |



댓글