반응형
Python으로 전처리 파이프라인 설계하기
파이프라인 이란
파이프라인(영어: pipeline)은 한 데이터 처리 단계의 출력이 다음 단계의 입력으로 이어지는 형태로 연결된 구조를 가리킨다. 이렇게 연결된 데이터 처리 단계는 한 여러 단계가 서로 동시에, 또는 병렬적으로 수행될 수 있어 효율성의 향상을 꾀할 수 있다. 각 단계 사이의 입출력을 중계하기 위해 버퍼가 사용될 수 있다.
이번 포스트에서는 간단히 데이터 셋을 로드하고 난 이후에 자동적으로 전처리가 가능한 간단한 전처리 파이프라인 (preprocessing pipeline)을 작성해 볼 예정입니다.
라이브러리
|
1
2
3
4
|
import pandas as pd
from sklearn.imput import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
from sklearn.pipeline import Pipeline
|
cs |
간단 샘플 데이터
|
1
2
3
4
5
6
7
|
data = {
"Name": ["Anna", "Bob", "Charlie", "Diana", "Eric"],
"Age": [20, 34, 23, None, 33],
"Gender": ["f", "m", "m", "f", "m"],
"Job": ["Programmer", "Writer", "Cook", "Programmer", "Teacher"]
}
|
cs |
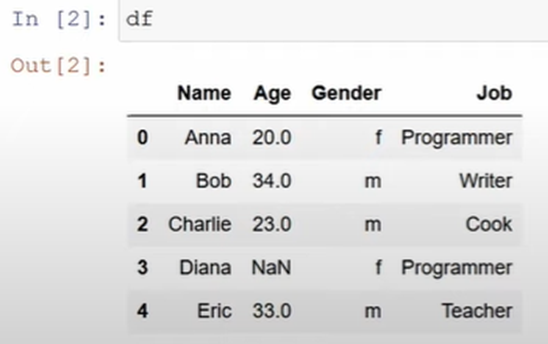
(실제로는 대용량 데이터일 수 있겠죠)
전처리 내용
- 이름(Name) 열 삭제 -
- 나이(Age)의 None 값 Impute하기 -
- 성별(Gender) 열 바이너리 값으로 전환하기 -
- 원핫 인코딩 적용하기 -
파이프라인 없이 전처리
1) 이름 (Name) 열 삭제하기
|
1
2
|
# Drop Name Feature
df = df.drop(["Name"], axis=1)
|
cs |

2) 나이(Age)의 None 값 Impute하기
|
1
2
3
|
# Impute Ages
imputer = SimpleImputer(strategy="mean")
df["Age"] = imputer.fit_transform(df[['Age']])
|
cs |

(Diana의 나이는 NaN였지만 Impute를 적용하고, 전체 나이의 평균 값으로 대체됐습니다.)
3) 성별(Gender) 열 바이너리 값으로 전환하기
|
1
2
3
4
5
6
|
# Numeric Gender
gender_dct = {
"m": 0,
"f": 1,
}
df['Gender'] = [gender_dct[g] for g in df['Gender']]
|
cs |

(성별 (Gender) 열 역시 m, f에서 뉴메릭 밸류로 전환됐습니다.)
4) 원핫 인코딩 적용하기
|
1
2
3
4
5
6
7
8
9
10
|
# OneHotEncode Jobs
encoder = OneHotEncoder()
matrix = encoder.fit_transform(df[['Job']]).toarray()
column_names = ["Programmer", "Writer", "Cook", "Teacher"]
for i in range(len(matrix.T)):
df[column_names[i]] = matrix.T[i]
df = df.drop(['Job'], axis=1)
|
cs |
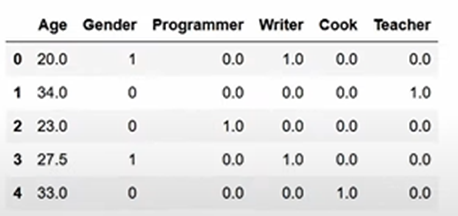
파이프라인으로 전처리
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
### Building a Pipeline ###
from sklearn.base import BaseEstimator, TransformerMixin
class NameDropper(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
return X.drop(['Name'], axis=1)
class AgeImputer(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
imputer = SimpleImputer(strategy="mean")
X['Age'] = imptuter.fit_transform(X[['Age']])
return X
class FeatureEncoder(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
# Numeric Gender gender_dct = {
"m": 0,
"f": 1,
}
X['Gender'] = [gender_dct[g] for g in X['Gender']]
# df
# OneHotEncode Jobs
encoder = OneHotEncoder()
matrix = encoder.fit_transform(X[['Job']]).toarray()
column_names = ["Programmer", "Writer", "Cook", "Teacher"]
for i in range(len(matrix.T)):
X[column_names[i]] = matrix.T[i]
return X.drop(['Job'], axis=1)
|
cs |
|
1
2
3
4
5
|
dropper = NameDropper()
imp = AgeImputer()
enc = FeatureEncoder()
enc.fit_transform(imp.fit_transform(dropper.fit_transform(df2)))
|
cs |
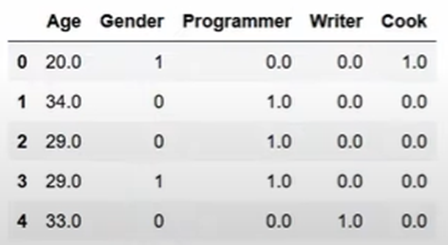
간단한 파이프라인으로 전처리
|
1
2
3
4
5
6
7
8
9
10
11
|
### Simple Pipeline ###
from sklearn.pipeline import Pipeline
pipe = Pipeline([
("dropper", NameDropper()),
("imputer", AgeImputer()),
("encoder", FeatureEncoder())
])
pipe.fit_transform(df2)
|
cs |
Full Code
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
|
import pandas as pd
data = {
"Name": ["Anna", "Bob", "Charlie", "Diana", "Eric"],
"Age": [20, 34, 23, None, 33],
"Gender": ["f", "m", "m", "f", "m"],
"Job": ["Programmer", "Writer", "Cook", "Programmer", "Teacher"]
}
df = pd.DataFrame(data)
# df
"""
Preprocessing Pipeline:
* Drop Name Feature
* Impute Ages
* Turn Gender into Binary / Numeric
* One Hot Encode Jobs
"""
from sklearn.imput import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
# Drop Name Feature
df = df.drop(["Name"], axis=1)
# df
# Impute Ages
imputer = SimpleImputer(strategy="mean")
df["Age"] = imputer.fit_transform(df[['Age']])
#df
# Numeric Gender
gender_dct = {
"m": 0,
"f": 1,
}
df['Gender'] = [gender_dct[g] for g in df['Gender']]
# df
# OneHotEncode Jobs
encoder = OneHotEncoder()
matrix = encoder.fit_transform(df[['Job']]).toarray()
column_names = ["Programmer", "Writer", "Cook", "Teacher"]
for i in range(len(matrix.T)):
df[column_names[i]] = matrix.T[i]
df = df.drop(['Job'], axis=1)
# df
### Building a Pipeline ###
from sklearn.base import BaseEstimator, TransformerMixin
class NameDropper(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
return X.drop(['Name'], axis=1)
class AgeImputer(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
imputer = SimpleImputer(strategy="mean")
X['Age'] = imptuter.fit_transform(X[['Age']])
return X
class FeatureEncoder(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
# Numeric Gender gender_dct = {
"m": 0,
"f": 1,
}
X['Gender'] = [gender_dct[g] for g in X['Gender']]
# df
# OneHotEncode Jobs
encoder = OneHotEncoder()
matrix = encoder.fit_transform(X[['Job']]).toarray()
column_names = ["Programmer", "Writer", "Cook", "Teacher"]
for i in range(len(matrix.T)):
X[column_names[i]] = matrix.T[i]
return X.drop(['Job'], axis=1)
data = {
"Name": ["Fiona", "Gerald", "Hans", "Isabella", "Jacob"],
"Age": [20, 34, None, None, 33],
"Gender": ["f", "m", "m", "f", "m"],
"Job": ["Writer", "Programmer", "Programmer", "Programmer", "Teacher"]
}
df2 = pd.DataFrame(data)
# df2
dropper = NameDropper()
imp = AgeImputer()
enc = FeatureEncoder()
enc.fit_transform(imp.fit_transform(dropper.fit_transform(df2)))
##
### Simple Pipeline ###
from sklearn.pipeline import Pipeline
pipe = Pipeline([
("dropper", NameDropper()),
("imputer", AgeImputer()),
("encoder", FeatureEncoder())
])
pipe.fit_transform(df2)
#
|
cs |
반응형
'공부 > 파이썬 Python' 카테고리의 다른 글
| Python을 사용한 유방암 검출 튜토리얼 (Breast Cancer Detection with Python) (1) | 2022.03.23 |
|---|---|
| Python에서의 실제 콜센터 프로세스 시뮬레이션 (0) | 2022.03.23 |
| 카운터와 딕셔너리의 차이 in Python (0) | 2022.03.20 |
| 다항식 회귀 (Polynomial Regression)이란 (0) | 2022.03.19 |
| 칼로리 트래커 / 대시보드 (1) (0) | 2022.03.18 |


댓글