Open Skills API 이용해서 세상 모든 직업 불러오기(feat. requests, json)
Open Skills.
A complete and standard data store for canonical and emerging skills, knowledge, abilities, tools, technolgies, and how they relate to jobs.
표준 및 새로운 기술, 지식, 능력, 도구, 기술 및 직무와 관련된 방법에 대한 완전하고 표준적인 데이터 저장소입니다.
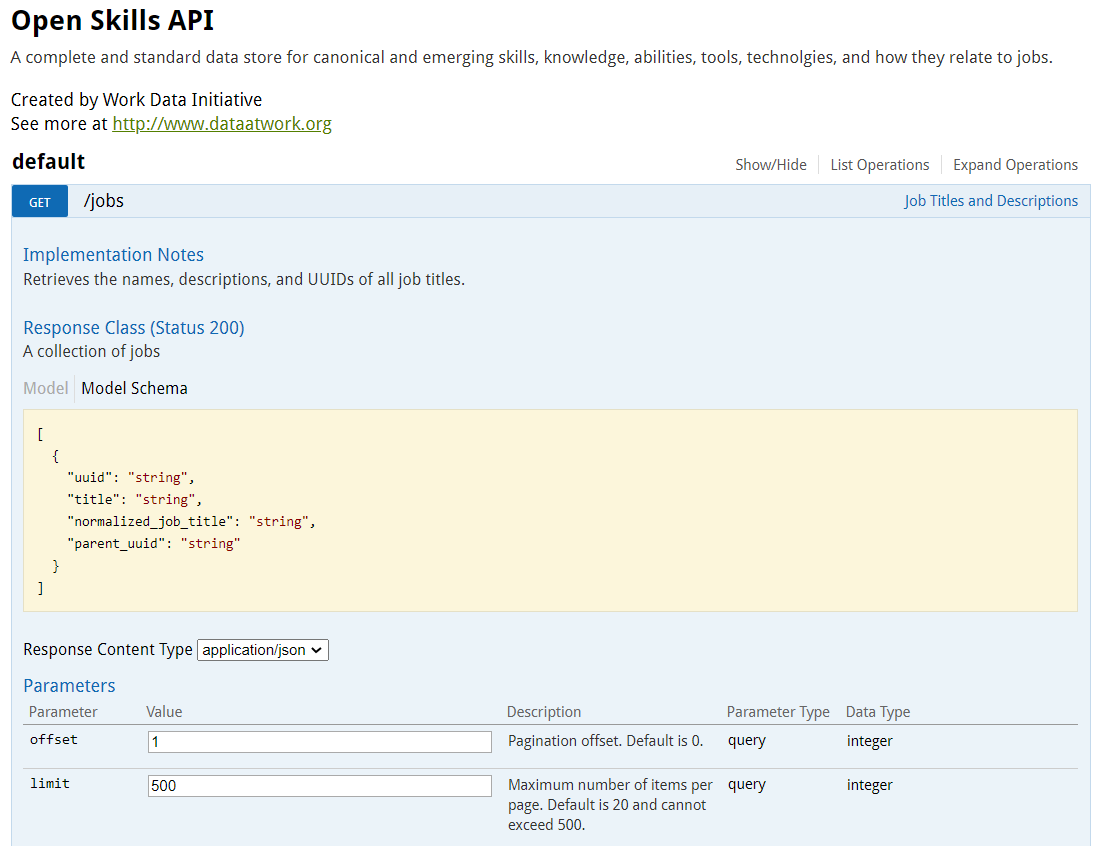
offset은 pagination을 뜻하고, 기본값은 0.
limit은 한 페이지에 몇 개의 아이템을 보이게 할 것인지를 말하고, 기본값은 20. 최대치를 넣어서 확인해보자.

return되는 json의 attribute을 보면 uuid, title, normalized_job_title, parent_uuid 총 4개의 attribute가 있습니다. 직업 고유의 ID와 직업의 이름, 직업을 포괄하는 부모 직업의 ID를 반환합니다.
Response Headers를 보면, x-total-count를 보니 46297.. 즉, 페이지가 46297까지 있다는 것입니다. 한 페이지에 최대로 보이게 할 수 있는 직업의 수는 500이니까, 46297 * 500을 하면 23,148,500개 입니다. 직업의 수가 정확히 23,148,500 개는 아니겠지만 굉장히 큰 숫자네요.

any-api.com/dataatwork_org/dataatwork_org/console/_jobs/GET
https://any-api.com/dataatwork_org/dataatwork_org/console/_jobs/GET
any-api.com
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
|
# Open Skills Project Web Page
# http://dataatwork.org/data/
# API Project Overview GitHub Page
# https://github.com/workforce-data-initiative/skills-api/wiki/API-Overview
# API Explanation
# http://api.dataatwork.org/v1/spec/
# Open Skills Research
# http://dataatwork.org/data/research/
# Representativeness Analysis
# http://dataatwork.org/data/representativeness/
# https://github.com/workforce-data-initiative/skills-analysis/blob/master/representativeness_analysis/Representativeness%20Analysis.ipynb
# Open Skills Documentation Site
# http://documentation.dataatwork.org/open-skills/
# Import Libraries
import requests
import json
import pandas as pd
import time
import multiprocessing
from openpyxl import Workbook
JOB_COUNT = 46298
def get_all_skills(count):# .csv 포맷 엑셀 파일 작성
print("S T A R T")
file_name = "OpenSkills_AllJobs"+str(count)+".csv"
ABC = ["A1", "B1", "C1", "D1"]
columns = ["uuid", "title", "normalized_job_title", "parent_uuid"]
write_wb = Workbook()
write_ws = write_wb.active
for (alphabet, col) in zip(ABC, columns):
write_ws[alphabet] = col
for i in range(count, count + JOB_COUNT/2, 1):
time.sleep(0.0002)
url = "http://api.dataatwork.org/v1/jobs?offset=" + str(count) + "&limit=500"
response= requests.request("GET", url)
res_json = str(response.json())
response = res_json.split("'}, {'")
# &limit을 포함하는 json은 직무능력과 관련된 데이터가 아님
for res in response:
if ("&limit" in res):
pass;
# string slicing
else:
uuid = res[res.find("'uuid':'")+12 : res.find("'title'")-3]
title = res[res.find("'title':")+10 : res.find("'normalized_job_title':")-3]
norm_title = res[res.find("'normalized_job_title':")+25 : res.find("'parent_uuid'")-3]
parent_uuid = res[res.find("'parent_uuid':")+16 :]
write_ws.append([uuid, title, norm_title, parent_uuid])
time.sleep(0.001)
if (i % 100==0):
print(count, i) # 100pg 마다 프로그레스 프린트
# 파일 저장
write_wb.save(file_name)
# M A I N
num_list = [0, JOB_COUNT/2] # 두 개 로 나눠서 진행 (가능하면 4개, 8개도 가능)
if __name__ == '__main__':
pool = multiprocessing.Pool(processes=4)
pool.map(get_all_skills, num_list)
pool.close()
pool.join()
|
cs |
API를 요청하고 응답 받는 데에 간혹 3초 이상 시간이 소요되는 경우도 있었습니다. 이렇게 긴 시간이 소요될 게 아니라고 생각했는데 굉장히 긴 시간이 소요됐습니다.
Json Handling 하는 데에 있어서 더 좋은 코드가 있는 것으로 알고 있습니다. Json 데이터를 처음으로 다루는지라 이해하는 데에 시간이 조금 걸렸습니다.

그래도 결국엔 저장한 파일은 잘 작성된 것을 확인할 수 있었습니다. 멀티 프로세스 2개로 설정했더니 너무 느린 것 같아서 결국 4개, 8개 늘려가면서 시도했습니다.
'공부 > 파이썬 Python' 카테고리의 다른 글
| 인디드 모든 구인공고 크롤링하기! (feat. Python, Selenium, BeautifulSoup) (0) | 2021.02.15 |
|---|---|
| Open Skills API 이용해서 세상 모든 직무능력 불러오기(feat. requests, json) (0) | 2021.01.15 |
| Skills Engine API 이용해서 모든 직업 불러오기 (feat. requests, json) (0) | 2021.01.14 |
| Emsi API 이용해서 직무 능력 불러오기 (feat. requests, json) (0) | 2021.01.14 |
| 커리어넷 API 직정보 불러오기 (feat. Python ElementTree) (0) | 2021.01.14 |



댓글